Learn how to scrape currency data from Hurriyet/Doviz using Python’s Beautiful Soup library and store it in Microsoft Fabric Lakehouse or Warehouse. Follow step-by-step instructions, install necessary libraries, handle potential webpage structure changes, and ensure proper data retrieval with effective techniques.

Introduction
In this article, we will scrape currency data from Hurriyet/Doviz (https://bigpara.hurriyet.com.tr/doviz/) using the Beautiful Soup library in Python. First, install the required libraries with the following commands:
pip install beautifulsoup4
pip install pandas
To handle slow network connections, introduce a delay in your code using the time.sleep() function to ensure the page fully loads. If the webpage’s structure has changed, identify and select the necessary elements manually as detailed below. Keep the browser window at its original size to avoid modifying the HTML structure.
Importing Python Libraries
For HTML Beautiful Soup, for spark connector, for dataframe pandas has imported.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime as dt
import com.microsoft.spark.fabric
from com.microsoft.spark.fabric import Constants
Logging in to Hurriyet/Doviz
Here, writing code for login into Hurriyet/Doviz, First, sending a get request to the URL and Identify the HTML document
#Url link
url= 'https://bigpara.hurriyet.com.tr/doviz/'
#Get url
html = requests.get(url)
#parse url
soup = BeautifulSoup(html.text)
In the web site, ABD Doları, Euro and İngiliz Sterlini inside div.dovizBar.mBot20.
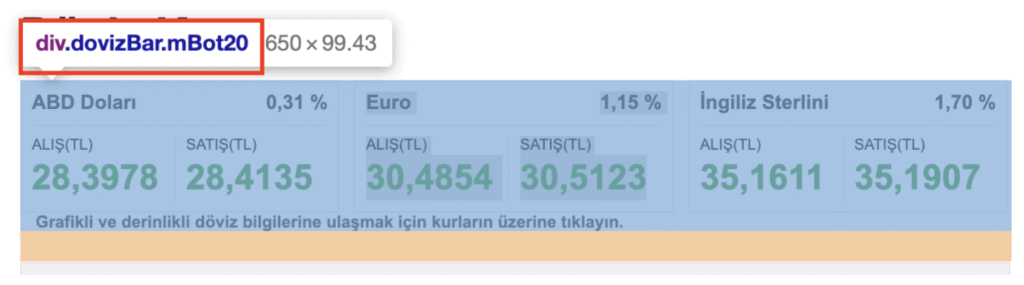
When inspecting Euro Alış(TL) which values inside span class=value. Therefore every ABD Doları, Euro and Sterlin values inside span class=value.
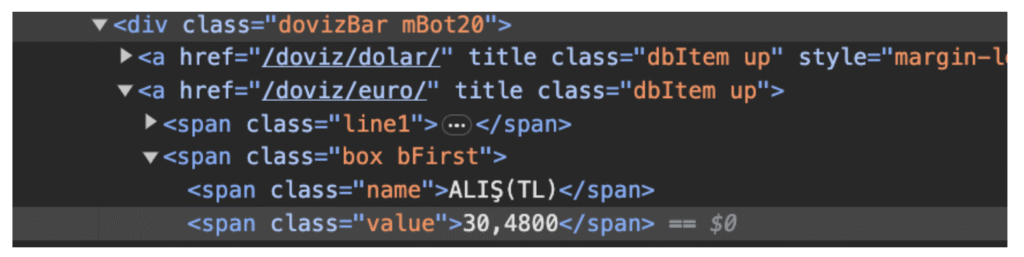
Having the HTML to USD , EURO and STERLIN. Let’s extract the information:
row_value = soup.find_all("span", {"class": "value"})
#usd value
usd=row_value[2].text
dolar=[usd]
#eur value
eur=row_value[5].text
euro=[eur]
#ster value
ster=row_value[8].text
sterlin=[ster]
#current date time
today_datetime = dt.datetime.today()
date_time=[today_datetime]
#current date
today_date = dt.date.today()
date=[today_date]
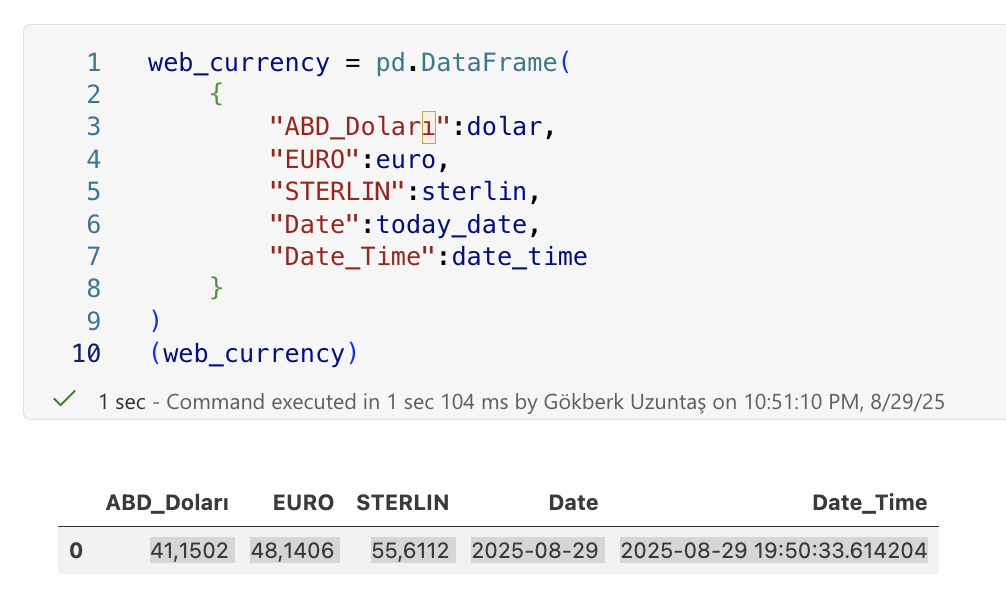
And creating as dataframe to use pandas in python.
web_currency = pd.DataFrame(
{
"ABD_Doları":dolar,
"EURO":euro,
"STERLIN":sterlin,
"Date":today_date,
"Date_Time":date_time
}
)
web_currency
The output code:
Let create a script with summarize:
dolar=[]
euro=[]
sterlin=[]
date=[]
date_time=[]
def cur_val():
#Url link
url= 'https://bigpara.hurriyet.com.tr/doviz/'
#Get url
html = requests.get(url)
#parse url
soup = BeautifulSoup(html.text)
#look row values
row_value = soup.find_all("span", {"class": "value"})
#usd value
usd=row_value[2].text
dolar=[usd]
#eur value
eur=row_value[5].text
euro=[eur]
#ster value
ster=row_value[8].text
sterlin=[ster]
#current date time
today_datetime = dt.datetime.today()
date_time=[today_datetime]
#current date
today_date = dt.date.today()
date=[today_date]
web_currency = pd.DataFrame(
{
"ABD_Doları":dolar,
"EURO":euro,
"STERLIN":sterlin,
"Date":today_date,
"Date_Time":date_time
}
)
return(web_currency)
The output code:

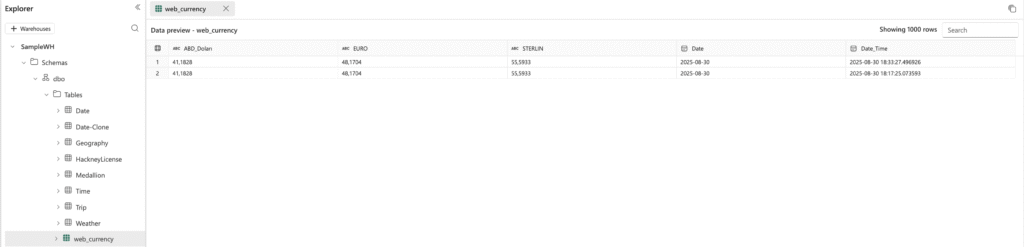
We now have a datas from Hurriyet/Doviz. We can store data to Lakehouse or Warehouse. Then import the data to Lakehouse or Warehouse test web_scrap_datas table.
# Make it Spark DataFrame
web_currency = spark.createDataFrame(web_currency)
# Write to Lakehouse (Delta table)
web_currency.write.format("delta").mode("overwrite").save("abfss://DevelopmentWS@onelake.dfs.fabric.microsoft.com/SampleLH.Lakehouse/Tables/web_currency")
#İmport spark connector library
import com.microsoft.spark.fabric
from com.microsoft.spark.fabric import Constants
#Write to Warehouse
web_currency.write.mode("append").synapsesql("SampleWH.dbo.web_currency")
Let’s consolidate all the scripts into a single, usable, and maintainable Python implementation.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime as dt
#Spark Connector
import com.microsoft.spark.fabric
from com.microsoft.spark.fabric import Constants
URL = "https://bigpara.hurriyet.com.tr/doviz/"
def fetch_rates() -> pd.DataFrame:
"""
Fetch the currency page, extract USD/EUR/GBP values, and return
a single-row pandas DataFrame with timestamps.
"""
#Request the page (raise on HTTP errors)
r = requests.get(URL, headers=HDRS, timeout=30)
r.raise_for_status()
#Parse HTML with an explicit parser
soup = BeautifulSoup(r.text, "html.parser")
#Select all spans that hold currency values (site-specific)
spans = soup.select("span.value")
if len(spans) < 9:
raise ValueError("Expected at least 9 currency elements (span.value).")
#Extract numbers by position (matches your original logic)
usd = spans[2].get_text(strip=True)
eur = spans[5].get_text(strip=True)
gbp = spans[8].get_text(strip=True)
#Build a one-row DataFrame with dates
now = dt.datetime.now()
today = now.date()
df = pd.DataFrame([{
"ABD_Doları": usd,
"EURO": eur,
"STERLIN": gbp,
"Date": today,
"Date_Time": now
}])
return df
def write_fabric(df: pd.DataFrame):
#Write the DataFrame into Microsoft Fabric (Lakehouse + Warehouse).
# Convert pandas to Spark
spark_df = spark.createDataFrame(df)
#Lakehouse (Delta-Parquet format). Prefer 'append' for ETL runs
spark_df.write.format("delta").mode("append").save(
"abfss://DevelopmentWS@onelake.dfs.fabric.microsoft.com/SampleLH.Lakehouse/Tables/web_currency"
)
#Warehouse table (append new rows)
spark_df.write.mode("append").synapsesql("SampleWH.dbo.web_currency")
def main():
#Fetch & print
web_currency = fetch_rates()
print(web_currency)
#try to write to Lakehouse/Warehouse
try:
write_fabric(web_currency)
print("✔ Write completed.")
except NameError:
#Error
print("Error")
if __name__ == "__main__":
main()
The output for Lakehouse:
The output for Warehouse: